
about Sliding Window2
Sliding Window pattern in algorithm, 滑动窗口套路
滑动窗口更多处理连续问题, “Longest Substring“, ”Subarray“
😼😼😼😼
Shortest Word Distance
Given a list of words and two words word1 and word2, return the shortest distance between these two words in the list.
Example:
Assume that words = ["practice", "makes", "perfect", "coding", "makes"].
“coding”
“practice”
"makes"
"coding"
For each a, we need to get the most recent position of b.
For each b, we need to get the most recent position of a.
這樣他們中差值最小的那個,就是我們需要的答案。
那麼在實現的時候,我們就需要從左到右掃一遍 array,並記錄:
IndexA:最近一次出現 a 的位置
IndexB:最近一次出現 b 的位置
Result:當前的最短距離
每當我們找到一個 a 或者 b 時,我們就要檢查 IndexB 和 IndexA 之間的差是否比 result 的值小,如果是,則更新 result 的值,直到遍歷完整個 array。
public int shortestDistance(String[] words, String word1, String word2) {
int index1 = -1, index2 = -1;
int minLen = Integer.MAX_VALUE;
for (int i = 0; i < words.length; i++) {
if (words[i].equals(word1)) {
if (index2 != -1) {
minLen = Math.min(minLen, i - index2);
}
index1 = i;
}else if (words[i].equals(word2)) {
if (index1 != -1) {
minLen = Math.min(minLen, i - index1);
}
index2 = i;
}
}
return minLen;
}
下面这种方法只用一个辅助变量 idx,初始化为 -1,然后遍历数组,如果遇到等于两个单词中的任意一个的单词,再看 idx 是否为 -1,若不为 -1,且指向的单词和当前遍历到的单词不同,更新结果,参见代码如下:
public int shortestDistance(String[] words, String word1, String word2) {
int idx = -1, res = Integer.MAX_VALUE;
for(int i = 0; i < words.length; i++) {
if (words[i] == word1 || words[i] == word2) {
if (idx != -1 && words[idx] != words[i]) {
res = Math.min(res, i - idx);
}
idx = i;
}
}
return res;
}
Shortest Word Distance III
This is a follow up of Shortest Word Distance. The only difference is now word1 could be the same as word2.
Given a list of words and two words word1 and word2, return the shortest distance between these two words in the list.
word1 and word2 may be the same and they represent two individual words in the list.
For example,
Assume that words = ["practice", "makes", "perfect", "coding", "makes"].
Given word1 = “makes”, word2 = “coding”, return 1.
Given word1 = "makes", word2 = "makes", return 3.
public int shortestDistance(String[] words, String word1, String word2) {
int idx = -1, res =Integer.MAX_VALUE;
for (int i = 0; i < words.length; ++i) {
if (words[i] == word1 || words[i] == word2) {
if (idx != -1 && (word1 == word2 || words[i] != words[idx])) {
res = Math.min(res, i - idx);
}
idx = i;
}
}
return res;
}
理解 words[i] != words[idx])
String[] words = new String[]{“practice”, “makes”, “makes”, “perfect”, “coding”};
String word1 = “makes”; String word2 = “coding”;
practice", "makes", "makes", "perfect", "coding
idx
i
res=max
i //(word1 == word2 || words[i] != words[idx])
idx // 这时候直接把idx移到i位置,res不更新,因为word1 != word2
res=max
字符串中的变位词
给定两个字符串 s1 和 s2,写一个函数来判断 s2 是否包含 s1 的某个变位词。
换句话说,第一个字符串的排列之一是第二个字符串的 子串 。
示例 1:
输入: s1 = "ab" s2 = "eidbaooo"
输出: True
解释: s2 包含 s1 的排列之一 ("ba").
示例 2:
输入: s1= "ab" s2 = "eidboaoo"
输出: False
使用两个数组统计 s1 中各字符的个数,看个数是否相等
class Solution {
public int minSubArrayLen(int target, int[] nums) {
if (s1.length() > s2.length()) {
return false;
}
int left = 0, right = 0;
int[] count1 = new int[26];
int[] count2 = new int[26];
while (right < s1.length()) {
count1[s1.charAt(right) - 'a']++;
count2[s2.charAt(right) - 'a']++;
right++;
}
if (Arrays.equals(count1, count2)) {
return true;
}
for (int i = s1.length(); i < s2.length(); i++) {
count2[s2.charAt(i) - 'a']++;
count2[s2.charAt(i - s1.length()) - 'a']--;
if (Arrays.equals(count1, count2)) {
return true;
}
}
return false;
}
}
字符串中的所有变位词
给定两个字符串 s 和 p,找到 s 中所有 p 的 变位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
变位词 指字母相同,但排列不同的字符串。
示例 1:
输入: s = "cbaebabacd", p = "abc"
输出: [0,6]
解释:
起始索引等于 0 的子串是 "cba", 它是 "abc" 的变位词。
起始索引等于 6 的子串是 "bac", 它是 "abc" 的变位词。
示例 2:
输入: s = "abab", p = "ab"
输出: [0,1,2]
解释:
起始索引等于 0 的子串是 "ab", 它是 "ab" 的变位词。
起始索引等于 1 的子串是 "ba", 它是 "ab" 的变位词。
起始索引等于 2 的子串是 "ab", 它是 "ab" 的变位词。
使用两个数组统计 s1 中各字符的个数,看个数是否相等
class Solution {
public int minSubArrayLen(int target, int[] nums) {
List<Integer> list = new ArrayList<>();
if(p.length() > s.length()) {
return list;
}
int[] count1 = new int[26];
int[] count2 = new int[26];
for (int i = 0; i < p.length(); i++) {
count1[p.charAt(i) - 'a']++;
count2[s.charAt(i) - 'a']++;
}
if (Arrays.equals(count1, count2)){
list.add(0);
}
for (int i = p.length(); i < s.length(); i++) {
count2[s.charAt(i) - 'a']++;
count2[s.charAt(i - p.length()) - 'a']--;
if (Arrays.equals(count1, count2)){
list.add(i - p.length() + 1);
}
}
return list;
}
}
l = “abcbac”, s = “ab”, return [0, 3] since the substring with length 2 starting from index 0/3 are all anagrams of “ab” (“ab”, “ba”)
only the count is from 1 to 0, we have ‘a’totally matched match == map.size(), we find an anagram
public List<Integer> allAnagrams(String sh, String lo) {
List<Integer> res = new ArrayList<>();
if (lo.length() == 0) {
return res;
}
if (lo.length() < sh.length()) {
return res;
}
Map<Character, Integer> map = countMap(sh);
int match = 0;
for (int i = 0; i < lo.length(); i++) {
// handle the rightmost ch at the previous sliding window
char ch= lo.charAt(i);
Integer count = map.get(ch);
if (count != null) {
map.put(ch, count - 1);
if (count == 1) {
match++;
}
}
// handle the leftmost ch at the previous sliding window
if (i >= sh.length()) {
ch = lo.charAt(i - sh.length());
count = map.get(ch);
if (count != null) {
map.put(ch,count + 1);
if (count == 0) {
match--;
}
}
}
if (match == map.size()) {
res.add(i - sh.length() + 1);
}
}
return res;
}
private Map<Character, Integer> countMap(String sh) {
Map<Character, Integer> map = new HashMap<>();
for (char ch : sh.toCharArray()) {
Integer count = map.getOrDefault(ch, 0);
map.put(ch, count + 1);
}
return map;
}
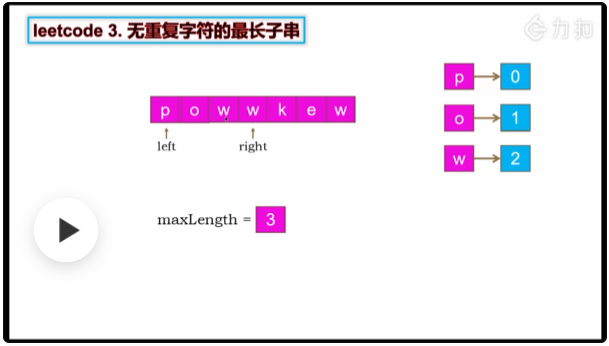
不含重复字符的最长子字符串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长连续子字符串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子字符串是 "abc",所以其长度为 3。
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子字符串是 "b",所以其长度为 1。
示例 3:
输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
示例 4:
输入: s = ""
输出: 0
滑动窗口: 时间空间都是 O(N)
public int lengthOfLongestSubstring2(String s) {
int n = s.length();
if (n <= 1) {
return n;
}
int maxLen = 1;
int left = 0, right = 0;
Set<Character> window = new HashSet<>();
while (right < n) {
char rightChar = s.charAt(right);
while (window.contains(rightChar)) {
window.remove(s.charAt(left));
left++;
}
maxLen = Math.max(maxLen, right - left + 1);
window.add(rightChar);
right++;
}
return maxLen;
}
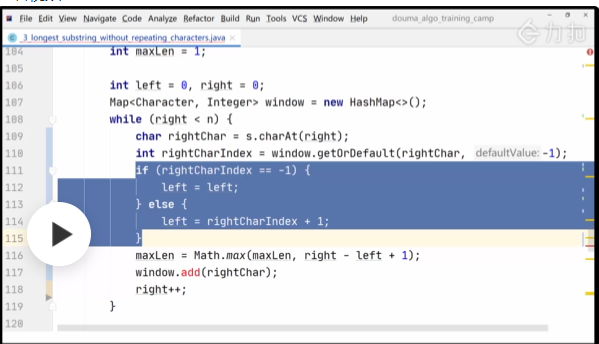
其实遇到重复字符, 直接跳到重复字符的后面, 滑动窗口: 时间空间都是 O(N)
public int lengthOfLongestSubstring2(String s) {
int n = s.length();
if (n <= 1) {
return n;
}
int maxLen = 1;
int left = 0, right = 0;
Map<Character, Integer> window = new HashMap<>();
while (right < n) {
char rightChar = s.charAt(right);
int rightCharIndex = window.getOrDefault(rightChar, 0);
left = Math.max(left, rightCharIndex);
maxLen = Math.max(maxLen, right - left + 1);
window.add(rightChar, right + 1);
right++;
}
return maxLen;
}
继续移动
slide window

slide window

slide window
slide window
输入: s = “p w w k e w” l r window[p] = 1 输出: 3
class Solution {
public int lengthOfLongestSubstring2(String s) {
int n = s.length();
if (n <= 1) {
return n;
}
int maxLen = 1;
int left = 0, right = 0;
int[] window = new int[128];
while (right < n) {
char rightChar = s.charAt(right); // p
// pwwkew
// {0, 0, 0}
// rightCharIndex = 0;前置,还没映射
int rightCharIndex = window[rightChar]; // 128个已经概括了不需要再 - ‘a’
left = Math.max(left, rightCharIndex);
maxLen = Math.max(maxLen, right - left + 1);
window[rightChar] = right + 1; // window[p] = 1;
right++; // r = 1
}
return maxLen;
}
}
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/MPnaiL
感谢:她们都有题库在 github 上直接有,都是大神
