
DDD in real project 2.5 database router
DDD in real project
understand database router
The starting point for considering self-developed database routing components is that the existing technical solutions cannot meet (unsuitable and inconvenient) personalized business needs.
And the self-developed components are small and refined, easy to iteratively maintain, and new functions can also be added later (For example, transaction support) Sub-database and sub-table are two different things. It may only sub-database without sub-table, may sub-table without sub-database, or may sub-database sub-table
what need to consider
- Dynamic switching of data sources
- hasing algorithm
- Cut point setting and data interception and repalce sql
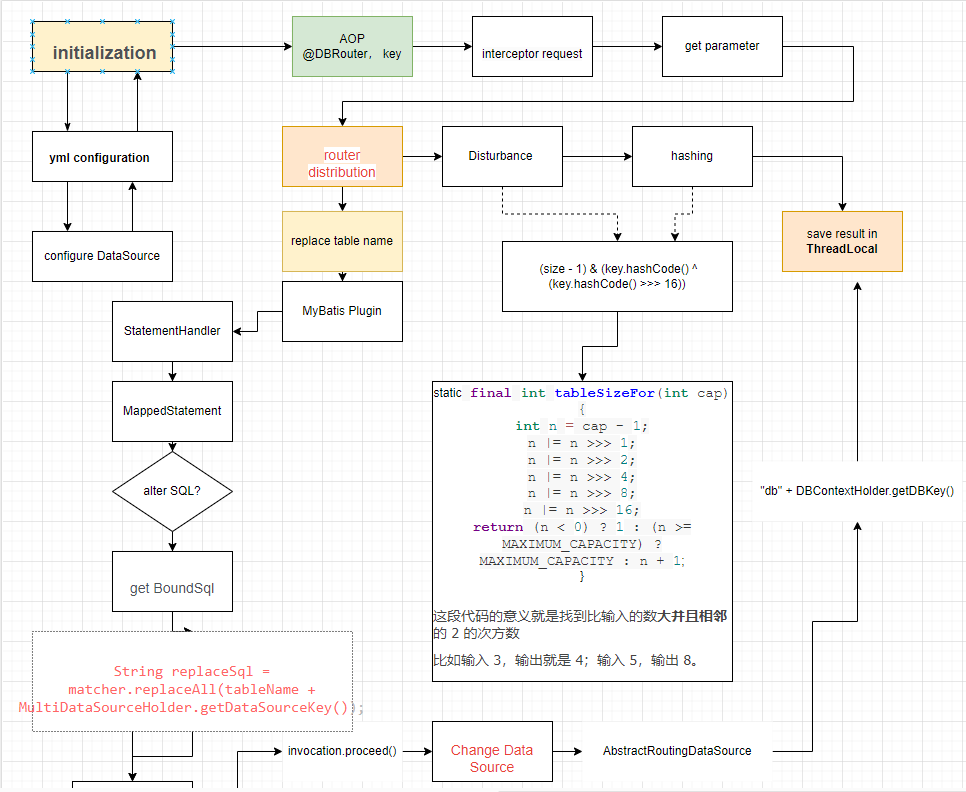
DDD ROUTER
hash
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
int n = cap - 1
给定的cap减1,是为了避免参数cap本来就是2的幂次方,这样一来,经过后续的未操作的,cap将会变成2 * cap,是不符合我们预期的。
n |= n >>> 1
n >>> 1,n无符号右移1位,即n二进制最高位的1右移一位;
n | (n >>> 1),导致的结果是n二进制的高2位值为1;
目前n的高1~2位均为1。
n |= n >>> 2
n继续无符号右移2位。
n | (n >>> 2),导致n二进制表示高3~4位经过运算值均为1;
目前n的高1~4位均为1。
n |= n >>> 4
n继续无符号右移4位。
n | (n >>> 4),导致n二进制表示高5~8位经过运算值均为1;
目前n的高1~8位均为1。
n |= n >>> 8
n继续无符号右移8位。
n | (n >>> 8),导致n二进制表示高9~16位经过运算值均为1;
目前n的高1~16位均为1。
n |= n >>> 16
n继续无符号右移16位。
n | (n >>> 16),导致n二进制表示高17~32位经过运算值均为1;
目前n的高1~32位均为1。
可以看出,无论给定cap(cap < MAXIMUM_CAPACITY )的值是多少,经过以上运算,其值的二进制所有位都会是1。再将其加1,这时候这个值一定是2的幂次方。当然如果经过运算值大于MAXIMUM_CAPACITY,直接选用MAXIMUM_CAPACITY。
为什么cap要保持为2的幂次方
HashMap中存储数据table的index是由key的Hash值决定的。在HashMap存储数据的时候,我们期望数据能够均匀分布,以避免哈希冲突。自然而然我们就会想到去用%取余的操作来实现我们这一构想。 这里要了解到一个知识:取余(%)操作中如果除数是2的幂次方则等同于与其除数减一的与(&)操作。 这也就解释了为啥一定要求cap要为2的幂次方。再来看看table的index的计算规则:
index = e.hash & (newCap - 1)
等同于:
index = e.hash % newCap
hashmap 中 hash问题
hash(K,V) 方法
HashMap中table的index是由Key的哈希值决定的。HashMap并没有直接使用key的hashcode(),而是经过如下的运算
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
而上面我们提到index的运算规则是e.hash & (newCap - 1)。由于newCap是2的幂次方,那么newCap - 1的高位应该全部为0。如果e.hash值只用自身的hashcode的话,那么index只会和e.hash低位做&操作。这样一来,index的值就只有低位参与运算,高位毫无存在感,从而会带来哈希冲突的风险。所以在计算key的哈希值的时候,用其自身hashcode值与其低16位做异或操作。这也就让高位参与到index的计算中来了,即降低了哈希冲突的风险又不会带来太大的性能问题。
按位异或运算(^):两个数转为二进制,然后从高位开始比较,如果相同则为0,不相同则为1。
扰动函数————(h = key.hashCode()) ^ (h >>> 16) 表示:
将key的哈希code一分为二。其中:
【高半区16位】数据不变。
【低半区16位】数据与高半区16位数据进行异或操作,以此来加大低位的随机性。
注意:如果key的哈希code小于等于16位,那么是没有任何影响的。只有大于16位,才会触发扰动函数的执行效果。
// egx: 110100100110^000000000000=110100100110,由于k1的hashCode都是在低16位,所以原样返回3366
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
case1:
h=高16位(全是0) and 低16位(有1)
h >>> 16 = 低16位全部消失,那么变成了32位(全是0)
h ^ (h >>> 16) = 原样输出
case2:
h=高16位(有1) and 低16位(有1)
h >>> 16 = 低16位全部消失,那么变成了高16位(全是0)and低16位(有1)
h ^ (h >>> 16) = 不是原样输出 将原高16位于原低16位进行扰动。
}
tech point
- AOP aspect interception: Intercept methods that need to use DB routing, here use custom annotations
- Database connection pool configuration: sub-database and sub-table need to configure database connection sources on demand, and perform dynamic data source switching in the collection of these connection pools
- AbstractRoutingDataSource: is a Spring service class for dynamic data source switching, providing an abstract method determineCurrentLookupKey for data source switching
- Routing hash algorithm design: During routing design, it is necessary to perform routing calculations based on the sub-database and sub-table fields, so that data can be evenly distributed to each database table.
- MyBatis interceptor: implement sql dynamic interception and modification
- router
- anotation
- DBRouter
@Documented @Retention(RetentionPolicy.RUNTIME) // ;ife circle @Target({ElementType.METHOD, ElementType.TYPE}) public @interface DBRouter { /** * router key * @return */ String key() default ""; }- DBRouterStrategy
@Documented @Retention(RetentionPolicy.RUNTIME) @Target({ElementType.TYPE, ElementType.METHOD}) public @interface DBRouterStrategy { /** *split table or not * @return */ boolean splitTable() default false; }- config
- DataSourceAutoConfig
- dynamic
- DynamicDataSource
public class DynamicDataSource extends AbstractRoutingDataSource { /** * 返回 db 路由 * @return aka db01, db02, ... */ @Override protected Object determineCurrentLookupKey() { return "db" + DBContextHolder.getDbKey(); } }- DynamicMybatisPlugin
- strategy
- impl
- DBRouterStratedyHashCode
- IDRouterStrategy
- impl
- util
- DBContextHoler
- DBRouterBase
- DBRouterConfig
- DBRouterJoinPoint
- anotation
modify SQL
SQL:SELECT * FROM tb_user WHERE id = 123;
TO
SQL:SELECT * FROM tb_user_01 WHERE id = 123;
StatementHandler
- prepare: used to create a concrete Statement object implementation class or Statement object
- parametersize: used to initialize Statement objects and assign values to sql placeholders
- update: used to notify the Statement object to push insert, update, delete operations to the database
- query: used to notify the Statement object to push the select operation to the database and return the corresponding query result
- The prepare method of StatementHandler intercepts sql statements
@Intercepts(
@Signature(type = StatementHandler.class, method = "prepare", args = {Connection.class, Integer.class})
)
- intercept method here is the method we want to implement, where invocation is the intercepted object
public interface Interceptor {
Object intercept(Invocation invocation) throws Throwable;
default Object plugin(Object target) {
return Plugin.wrap(target, this);
}
default void setProperties(Properties properties) {
// NOP
}
}
- How to get the SQL statement in MyBatis? Based on StatementHandler, then get its BoundSql
// 获取 StatementHandler
StatementHandler statementHandler = (StatementHandler) invocation.getTarget();
MetaObject metaObject = MetaObject.forObject(statementHandler, SystemMetaObject.DEFAULT_OBJECT_FACTORY,
SystemMetaObject.DEFAULT_OBJECT_WRAPPER_FACTORY, new DefaultReflectorFactory());
MappedStatement mappedStatement = (MappedStatement) metaObject.getValue("delegate.mappedStatement");
// 获取 MyBatis 原始 SQL
BoundSql boundSql = statementHandler.getBoundSql();
String originalSql = boundSql.getSql();
- How to identify table names in SQL? Use regular expressions to match: from, into, update these three keywords, followed by the table name
private Pattern pattern = Pattern.compile("(from|into|update)[\s]{1,}(\w{1,})", Pattern.CASE_INSENSITIVE);
- How to replace after identification? Use reflection to directly modify the BoundSql#sql field
/ 通过反射修改 sql 语句
// getDeclaredField:可以获取所有已声明字段(无视访问限定符); getField:只能获取public 字段
Field field = boundSql.getClass().getDeclaredField("sql");
field.setAccessible(true);
field.set(boundSql, replacedSql);
field.setAccessible(false);
AOP aspect interception
- Pointcut
encapsulate
Finally, encapsulate the project into a SpringBoot starter dependency, write a configuration class, and then use the automatic assembly mechanism
@Configuration
public class DataSourceAutoConfigure implements EnvironmentAware {
about test need resources- > mybatis -> mapper
- UserStrategyExport_mapper.xml … or this xml ro test
@Resource
private IUserStrategyExportDao UserStrategyExportDao;
